Human Robot Collaboration with Reinforcement Learning
Overview
This project allows for human robot collaboration with the help of an assistive agent which minimally adjusts the human actions to improve the task performance without any prior knowledge or restrictive assumptions about the environment, goal space or human policy. This is an adaptation of model free constrained residual policy using proximal policy optimization for shared control. It has been tested on Lunar Lander and Franka Reach environments.
Here a joystick is used to interact with the environment, the human uses the joystick to get the human actions while the constrained residual policy provides the assistive actions, a combination of both acts as the actual action that the environment receives.
Proximal Policy Optimization
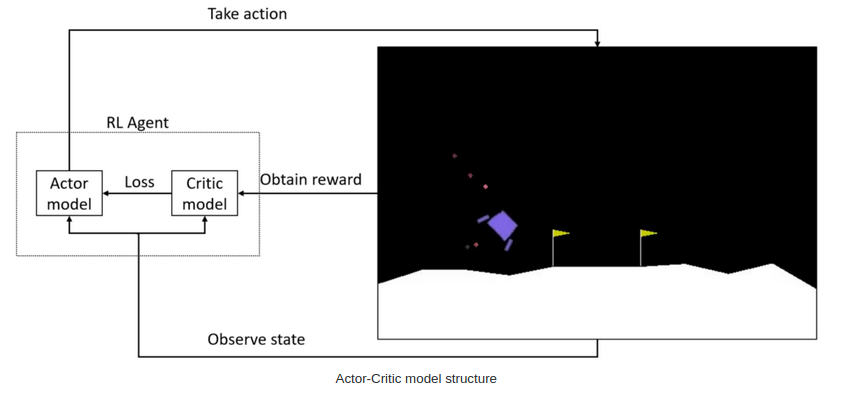
Proximal Policy Optimization is an on-policy reinforcement learning method where experiences are collected in batches to update the decision-making policy. It maintains policy continuity by clipping updates, striking a balance between variance and bias. It employs an Actor-Critic approach using a neural net with 3 layers, 128 units each, taking environment observation or state as inputs and producing actions as outputs.
Behavioral cloning
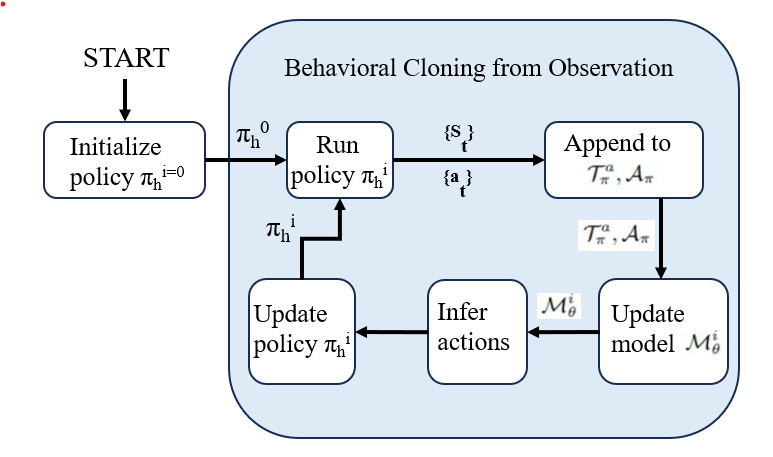
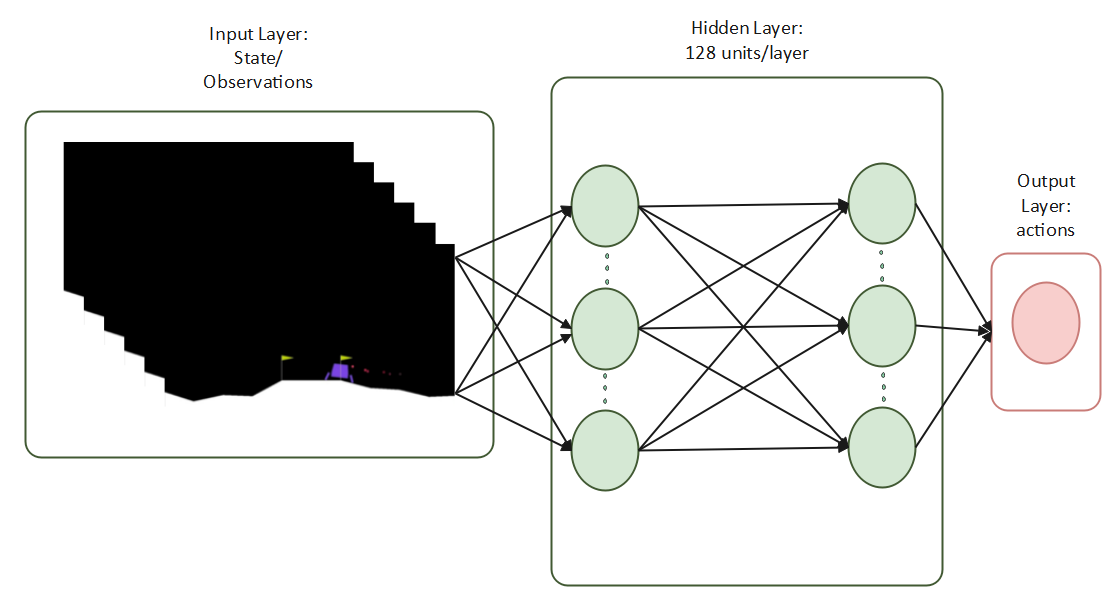
To make training more efficient due to high sample requirements of methods like PPO, a surrogate policy πh> is used instead of the human policy for training a shared autonomy agent. The behavioral cloning agent, which emulates the human policy, is a 3-layer neural network with 128 hidden units per layer. It's trained using data from human interactions in the environment.
Residual Learning Policy
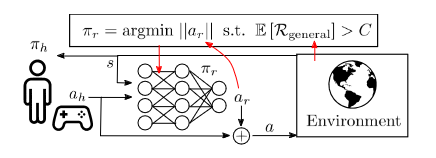
Residual policy learning uses a baseline policy π0 to reduce the sample complexity of reinforcementlearning methods. The learned policy acts by adding a “residual” or corrective action ar ∼ π(s, a0) to the action a0 ∼ π0(s) provided by the nominal policy. The residual agent can be trained using any reinforcement learning algorithm that allows for continuous action spaces, in this case a version of constrained proximal policy optimization was implemented and π0 is replaced with a human actor. During traing the human actor is replace with the human surrogate πh, the pretrained using behavioral cloning policy.

The assistive agent is also a 3 layer neural network with 128 hidden units per layer and 2 heads, one for the policy and other for the value function with the state and human action as inputs. Learn more about this algorithm here
Lunar Lander
The goal of the lunar lander game is to land the spaceship inbetween the flags using its 3 thrusters to control its motion. It has a 2 dimensional action space and an 8 dimensional observation space in the continuous environment. The human surrogate policy trains over 80 episodes and the residual policy is trained over 10,000 episodes resulting in assistive actions that significantly improve the results.
Franka Panda
The goal for the FrankaReach environment is for the end effector to reach the desired position where the reward is based in the distance from this desired goal position. This environment uses an Inverse Kinematics controller to move the end effector in the x, y and z planes, therefore has a 3 dimensional action space and a 6 dimensional observation space. In my version, the desired goal can be set by the user or be random.
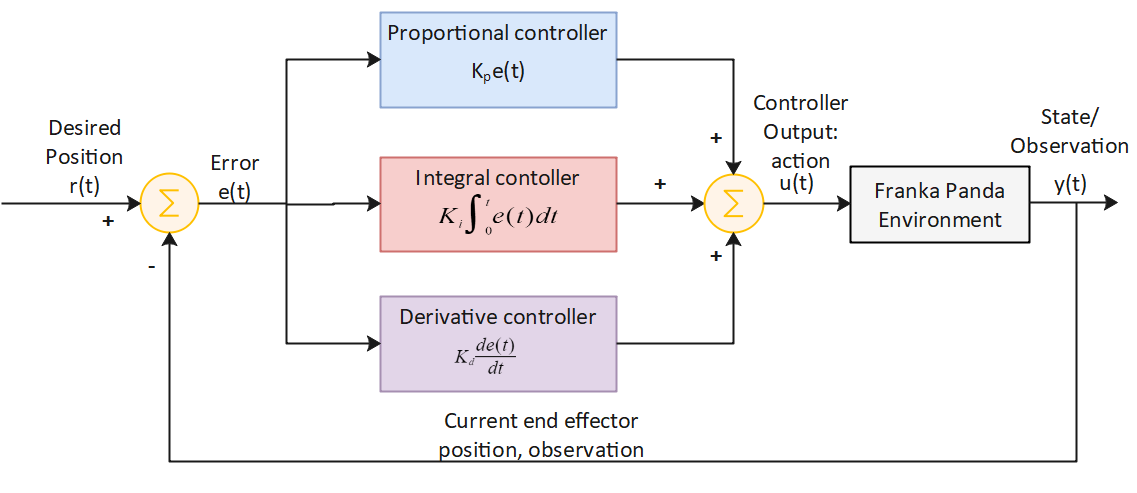
A PID controller was used as a human surrogate policy instead of the behavior cloning neural network, since training a good agent through behavioral cloning was requiring a lot of data collected from human. After training the residual policy for 10,000 epsiodes, the assistive actions were successful in improving the efficiency of reaching the goal in reducing the overall time required and the total score.
Franka with Multiple Goals
The multi-goal FrankaReach is a new environment designed such that there are 2 goals, a red and a green one. The reward is such that the penalty for being at a distance from the green goal is double the penalty for being at a distance from the red one. The point of this experiment was to observe the behaviour of the assistive agent if the human agent tried to reach the red agent. It was observed that the assistive agent prioritized the goal that was closest to the end effector.
Results

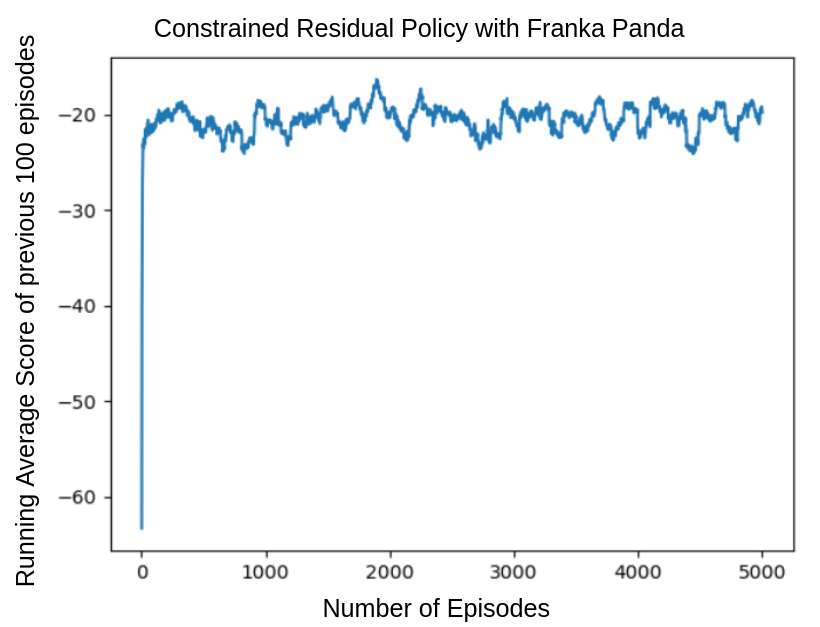
The above plots shows the accumulated rewards of the environment as it trained. In both the environments it is observed that the assistive agent, inspite of take very minimal actions does infact improve the humans ability to acheive the goals successfully. The total score and the time taken to reach the goal in case of the Franka Reach environment were the metrics used to ascertain the impact of the assistive agent.

Know more about this project at this github link .
- © Untitled
- Design: HTML5 UP